安装: pip install scrapy
安装可能会出现问题,此时需要下载一个依赖包
在 这个网站: https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

下载对应版本,,注意,,python3.6 adm64位对应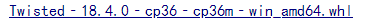
pip install 文件的完成路径
安装成功后
开始使用:
创建项目:scrapy startproject 项目名
目录结构如下:
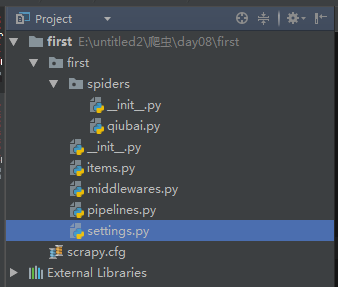
生成爬虫文件:终端cd进入到 first目录下
执行命令:scrapy genspider 文件名(name) 网站网址(url)
运行爬虫:终端cd到spiders目录下
执行命令:scrapy crawl name
在此过程会遇到一些问题
(1)需要安装pywin32
(2)需要配置setting文件
(a)把True改为False,不遵从robots协议

(b)创建头部信息
现在可以执行了